
2022-11-01 11:31:48
来源:渊亭科技
近年来,强化学习技术在游戏、技术科学领域取得了优异的表现,如 DeepMind 的 AlphaGo Zero 在围棋比赛中击败人类顶尖围棋高手、OpenAI Five 训练的智能体在 Dota2 5v5中击败人类玩家等。但是,作为机器学习的重要分支之一,强化学习也同样面临着可解释性不足的痛点,即在实际应用中“难以被理解”,也因此“难以被信任”,这导致了强化学习在对安全敏感的业务领域(比如医疗、自动驾驶等)发展受到了较大的限制。
DataExa-Nash 多智能体
渊亭科技推出的面向决策智能应用场景的「多智能体分布式学习框架DataExa-Nash」,是一个面向作战指挥、无人系统集群协同、策略仿真等智能决策场景的高性能系统,为多智能体模型的设计、训练、发布、对抗模拟和复盘分析等任务过程提供全生命周期支撑。
DataExa-Nash在集成多种SOTA多智能体算法(MAPPO、MADDPG、QMIX、RODE等)的基础上,统一了深度强化学习算法开发范式和评估体系,简化了开发进程,研究人员使用该框架可以大大降低多智能体开发的难度。
同时,DataExa-Nash提供了高效的分布式并行训练能力,可用于创建并行性更强的智能体,特别适用于不完备信息、非稳态环境下的推理决策,比如策略游戏(星际争霸等)、常规棋类(围棋象棋等)、无人系统(无人机集群协同等)、机器人操作、作战指挥(仿真推演等)等各种复杂决策场景。
DataExa-Nash中的可解释性技术
强化学习过程中智能体(Agent)和环境(Environment)往复交互,智能体不断从环境中学习和探索如何获取最大奖励值(Reward),逐步构建行为(Action)决策能力。DataExa-Nash围绕强化学习核心要素-环境和智能体(任务的建模,被蕴含在平台固化的能力和设计过程中),进行可解释性特性的构建。具体如下图所示:
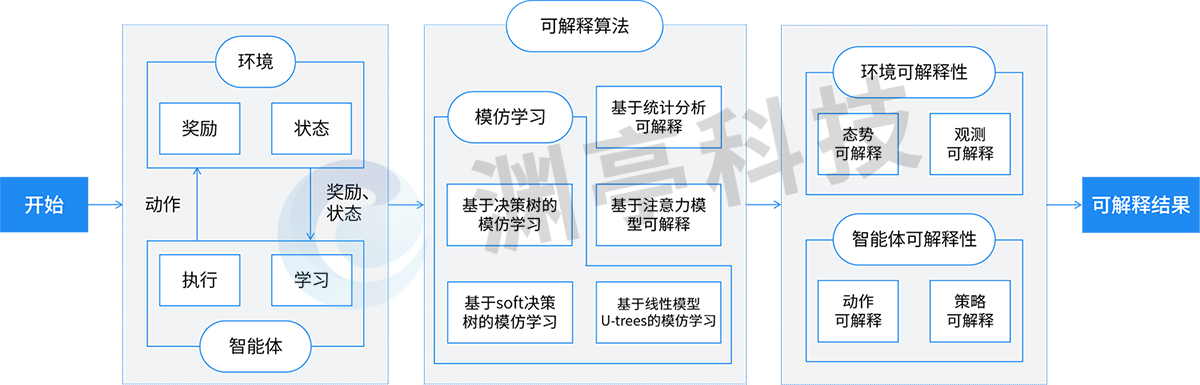
DataExa-Nash可解释技术示意
DataExa-Nash可解释技术示意展现了Nash和可解释性相关的主要流程及采用技术,Nash基于诸多可解释算法对智能体和环境交互过程进行拆解,形成环境可解释性和智能体可解释性。
1.DataExa-Nash可解释性基础
DataExa-Nash中集成了多种可解释性算法,如基于决策树的模仿学习、基于线性模型U-trees的模仿学习、基于Soft决策树的模仿学习、基于注意力模型可解释及基于统计分析可解释等算法。DataExa-Nash集成了模仿学习类型的可解释性算法,可以很好的利用已经具备可解释性的算法对智能体行为进行解释;集成了注意力类型的可解释性算法,可以对环境中全局态势和单个观测态势进行解释;基于统计分析可解释方法,可以对态势、行为及奖励等特征对智能体决策的影响进行分析,从而产生决策的可解释性。
2.环境可解释性
环境可解释性是指对环境中态势转移的内部机理进行解释。在强化学习中,环境是具备一定的黑盒性的。环境可解释性的构建,有利于理解环境态势变化对智能体决策可能的影响,更准确
3.智能体可解释性
DataExa-Nash-可解释性技术的应用案例
1.基于星际争霸Ⅱ的可解释技术应用
星际争霸Ⅱ是由暴雪娱乐在2010年7月27日推出的一款即时战略游戏,是《星际争霸》系列的第二部作品。DataExa-Nash 基于注意力模型在星际争霸Ⅱ地图构建5个红方智能体角色和7个电脑角色对战的场景,通过分析环境中哪些态势信息对智能体决策影响最大,即找到决策关键关联因素,为智能体的决策提供解释,具体效果如下图所示。
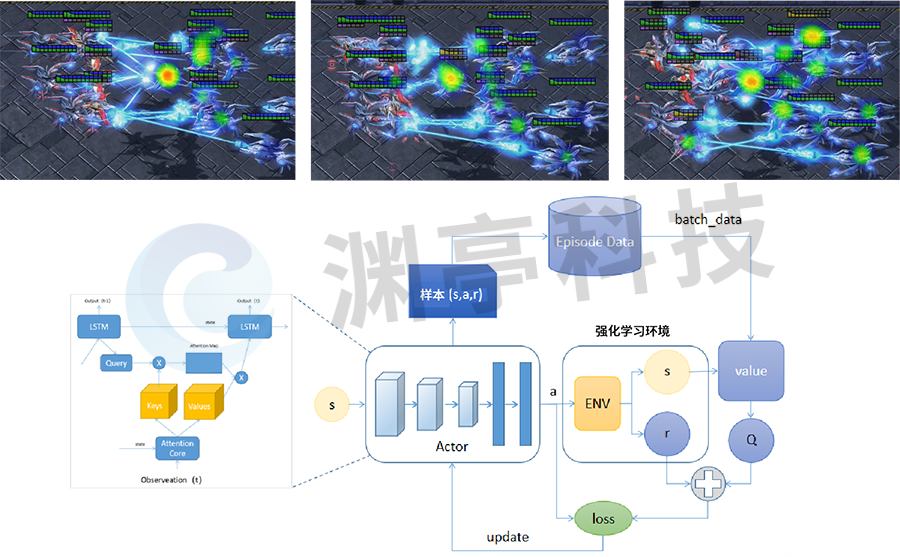
图 1 基于注意力模型的星际争霸Ⅱ可解释性
DataExa-Nash 中基于注意力模型,观测在星际争霸Ⅱ智能体和电脑的对抗过程中敌方各个态势对智能体决策的影响,判定敌方单元血量和敌方单元火力在决策过程中的影响最为明显。从左侧第一个图至最后一个图,展现了智能体根据观测到的敌方态势变化调整射击动作决策的过程,由开始集中火力攻击某个电脑角色,到随着敌方该角色血量逐渐变少,射击逐步集中到其它威胁较大的智能体上。
2.基于兵棋推演的可解释技术应用
六角格地图的兵棋推演仿真环境是一种典型的仿真环境,这类环境模拟了多种复杂的地理环境(如高程、居民地、丛林、道路等),并包含有丰富的兵棋算子(如重型坦克、中型战车、无人战车、炮兵等)。探索该模式下强化学习训练智能体的决策可解释性,非常具有典型性。DataExa-Nash 可以接入此类环境,使用基于注意力模型、基于数据等方式,进行可解释性的探索,具体过程如下图所示。
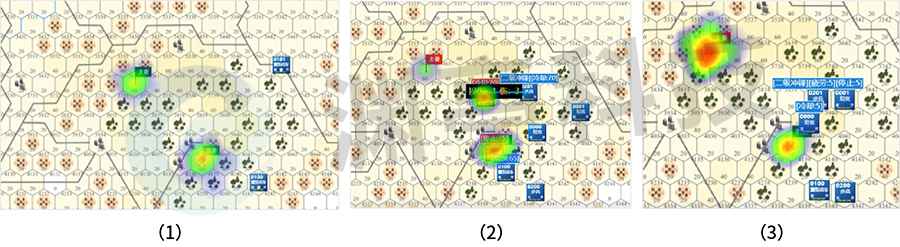
图 2 基于注意力模型的兵棋智能体可解释性
以上是一次典型的推演过程中,DataExa-Nash 利用注意力机制分析计算的关键决策节点,对节点的行为进行可解释性的计算和输出。该模式基于群队想定下蓝方智能体的视角进行训练,智能体决策过程关注战场态势变化。其中图(1)展现蓝方未发现敌方且夺控点均未被夺控,蓝方智能体的决策观点基本为抢占主夺控点和次要夺控点,此时智能体主要动作合集(移动)都是为了到达夺控点然后进行夺控;图(2)蓝方智能体发现了红方,此时智能体的关注点转移到了红方目标,智能体动作合集主要动作由之前的移动变为了攻击;图(3)蓝方智能体发现主要夺控点被夺控,主夺控点关注度明显变高。
除注意力机制之外,DataExa-Nash 也可以基于数据开展可解释性分析(例如基于多局智能体推演决策数据统计结果进行分析,如下图),实现深度强化学习模型的可解释,直观展示得到模型结果的关键信息。
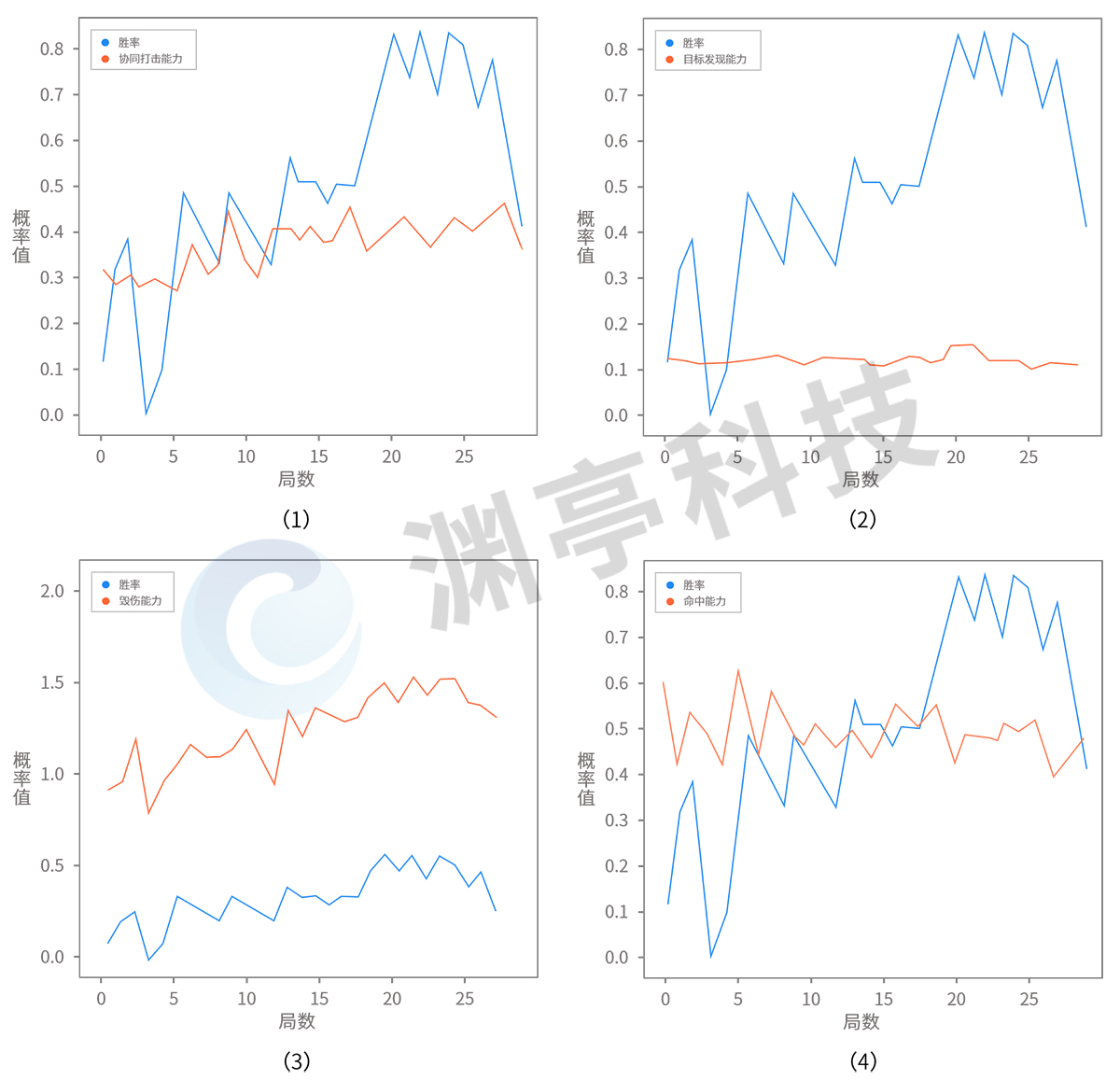
图 3 基于数据的兵棋智能体可解释性
以上展示了智能体不同能力(如协同打击能力、毁伤能力、目标发现能力等)对最终胜率的影响。图(1)是智能体协同打击能力与胜率曲线变化;图(2)是智能体的目标发现能力与胜率曲线变化;图(3)是智能体的毁伤能力与胜率曲线变化;图(4)是智能体命中能力与胜率曲线变化。可以明显发现智能体的毁伤能力和协同打击能力对最终胜率影响最大。
延伸阅读:
关于强化学习缺乏可解释性
强化学习缺乏可解释性的主要表现如下:
(1)如同黑盒一般难以理解。对于普通用户而言,经典强化学习在应用深度神经网络(Deep Neural Networks,DNN)模型后,表现得愈发复杂,如同一个黑盒:给它一个态势信息作为输入,经过一定计算,反馈决策结果。无法确切地知道背后的决策依据以及做出的决策是否可靠。由于缺乏可解释性,强化学习策略的可靠性经常受到挑战,从而也给强化学习在实际场景应用中带来非常大的阻碍。
(2)难以评估是否学到现实有用的知识。目前强化学习应用在仿真环境中具有优异表现,如 OpenAI Gym、星际争霸II等,但仿真与真实世界往往存在一定的差异,很难做到完全与真实场景完全一致。而强化学习在仿真环境下开展大规模训练时,难以避免对仿真环境的过拟合。当过拟合发生时,模型学到的知识是否在现实场景下同样有效,没有一套有效的评估手段和解释。
(3)难以评估学到的知识对环境变化的适应性。强化学习的策略通常与环境存在强耦合。在仿真环境训练过程中,经常出现只是对仿真环境参数做出较小修改,都会导致强化学习无法给出合理的决策。在实际应用中,也就难以确定强化学习训练出来的模型是否具备较好泛化性,能够适应环境的变化。
强化学习可解释性(Explainable Reinforcement Learning,XRL)是人工智能可解释性(Explainable Artificial Intelligence, XAI)的子问题。为了克服强化学习可解释差的弱点,行业内开展了大量的相关研究。目前,强化学习可解释技术的研究仍处于发展的初期阶段,且很多技术直接继承于人工智能可解释性。
1.可解释性概念
可解释性是人与决策模型之间知识体系连接的桥梁,它既是决策模型的准确代理,也是人所可以理解的。具体说来,强化学习可解释性技术,主要是帮助人理解模型是如何工作的,进而对模型结果的置信度建立概念:它从环境中学到了什么,是否学到了真正的知识,知识的应用是否具备一定鲁棒性,针对每个态势输入它为什么会做出这样的决策、以及它所做的决策是否可靠的。
2.可解释性技术
可解释性技术通常分为事前可解释性(Ante-Hoc)和事后可解释性(Post-Hoc)。其中事前可解释性指通过训练结构简单、可解释性好的模型或将可解释性结合到具体的模型结构中的自解释模型,从而让模型本身具备一定可解释能力。事后可解释性又划分为全局可解释性和局部可解释性,其中全局可解释性是对模型的整体逻辑和内部工作机制进行解释,局部可解释性是针对模型决策过程和决策结果进行解释。
3.强化学习可解释方法
强化学习可解释性方法有:基于视觉感官的解释、基于模仿学习的解释、基于分层强化学习的解释等。
(1)基于视觉感官的解释是通过对输入态势信息对动作的影响,对关键信息进行局部高亮显示,从而让人直观上了解到模型决策的依据,常见的可解释方法有基于注意力模型强化学习方法、基于扰动的显著性方法等。
(2)基于模仿学习的解释是利用具备较强解释能力的模型对强化学习训练的智能体进行行为的克隆学习,从而利用自身可解释性对智能体的决策进行解释,常见的可解释方法有基于线性模型U树的模仿学习、基于决策树混合专家树的模仿学习、基于软决策树模型的模仿学习等。
(3)基于分层强化学习的解释是根据相近的动作是为了完成同一个目标的特点,将决策序列划分为多个子任务,从而实现对模型从策略层面进行解释,常见的可解释方法有基于符号深度强化学习框架的解释算法、基于点对点的可解释的分层强化学习、基于奖励分解的最小需求解释算法等。



















