2020-07-16 14:12:03
来源:深信服科技
市场增长的主要驱动力源于当前日益复杂的网络安全形势,网络犯罪和黑客攻击的规模和频率不断增加,且黑客不断试水新技术来进行攻击,未知威胁频发。安全团队对于未知威胁的抵御越来越捉襟见肘,行业开始寻求更先进的解决方案来抵御未知威胁。深信服认为,为达成上述效果,在未知威胁检测方面,AI技术具有不可替代的优势。
为什么利用AI能够检测未知威胁?
泛化能力越强,检测未知威胁的能力就越强, 检出率就越高。
随着新型病毒的大量出现以及网络攻击的愈加频繁,现在业界普遍使用的基于规则或特征码的检测方案的有效性正在变得越来越低。一方面,黑白名单和传统特征规则只能处理已知的恶意软件,而对于未知攻击,这类检测方案的效用通常很低。另一方面,攻击者的技术升级,新型恶意软件越来越多,安全专家通过人工分析恶意样本以提取新规则或特征码的难度大大增加。
而基于人工智能的恶意文件查杀引擎优于传统基于特征码的查杀引擎,原因在于机器学习、神经网络等AI技术具有泛化能力,通过使用已知样本进行训练就可以在未知样本集达到很好的效果,因此可以发现新型的恶意文件。
以黑样本为例,在攻击手段迭代更新的过程中,黑客并不总是另起炉灶来重新制作攻击向量。他们常常是通过对现有攻击手段进行优化、整合和更新,进而实施下一次攻击。因此,未知威胁和已知威胁通常具有某种意义上的相似性。而AI检测算法就是期望通过对已知数据的学习,提取其中的固定模式,最终达到检测相似未知的目的。相似的,白样本的演进流程中同样存在这样的比变量,比如开发代码复用等。综上所述,安全检测场景中的泛化能力其本质是检测算法是否能够提取潜在的固定模式,进而在相似样本集上输出一致的检测结果。
那么,如何评估检测算法的泛化能力呢?
基于前面对泛化能力的分析,深信服安全专家给出了检测算法泛化能力的一个评估方法:检测算法的泛化能力等同其对相似样本检测结果的一致性。
简单来说,可以通过以下两步来衡量一个检测算法的泛化能力:
1. 定义样本相似性,用来描述你的泛化需求。比如指定相差10条指令的恶意文件为相似文件,那么你所关注的就是在已知样本和未知样本拥有10条指令差异下的泛化检测能力。
2. 统计检测算法在这些相似样本上的结果一致性。一致性是表示检测算法输出的统一程度,具有强泛化能力的检测算法应当在相似样本上输出相同的检测结果。因此,一致性越高,则说明算法的泛化能力越强;反之,泛化能力越弱。
泛化能力的量化评估公式具体如下:
1. 随机选取N个样本集,每个集合内的样本相互间具有相似性,标记为S1,S2,...,SN。
2. 对每一个集合Si, 评估检测算法的结果一致性。假设Si 有M 个样本,将算法的检测结果序列记为o1,o2,...,oM,计算o1,o2,...,oM表征的熵,记为ei。假设此检测任务的理论最大熵值为E,则可以使用E-ei表征算法对Si的结果一致性。
3. C= E- (e1 + e2 + ... + eN)/N 则表征了算法在整个样本集上的平均一致性, 即泛化能力。
业界引擎的泛化能力分布
目前很多安全产品中都集成了恶意文件检测能力,在Virustotal平台上就有70多家的恶意文件检测引擎。从公开信息上看,不少检测引擎都标称采用了机器学习算法。那么现在业界检测引擎的泛化能力到底如何,AI检测引擎之间是否有差异?
我们构建了包含15万黑样本的共7256个相似样本集。这些样本覆盖了2019.1.1~2020.5.20期间的线上热门样本。此外,通过VT平台获取70+业界引擎对相似样本集的检测结果(手动触发重分析,确保为引擎最新结果),以公平比较他们的泛化能力。如下图所示。图中的每一个点对应VT上一种检测引擎,其中蓝色的点表示深信服SAVE引擎的AI模型在不同配置下的效果;黄色实心点表示可从公开信息确认的业界机器学习引擎;灰色的点表示技术路线未知的其他引擎。
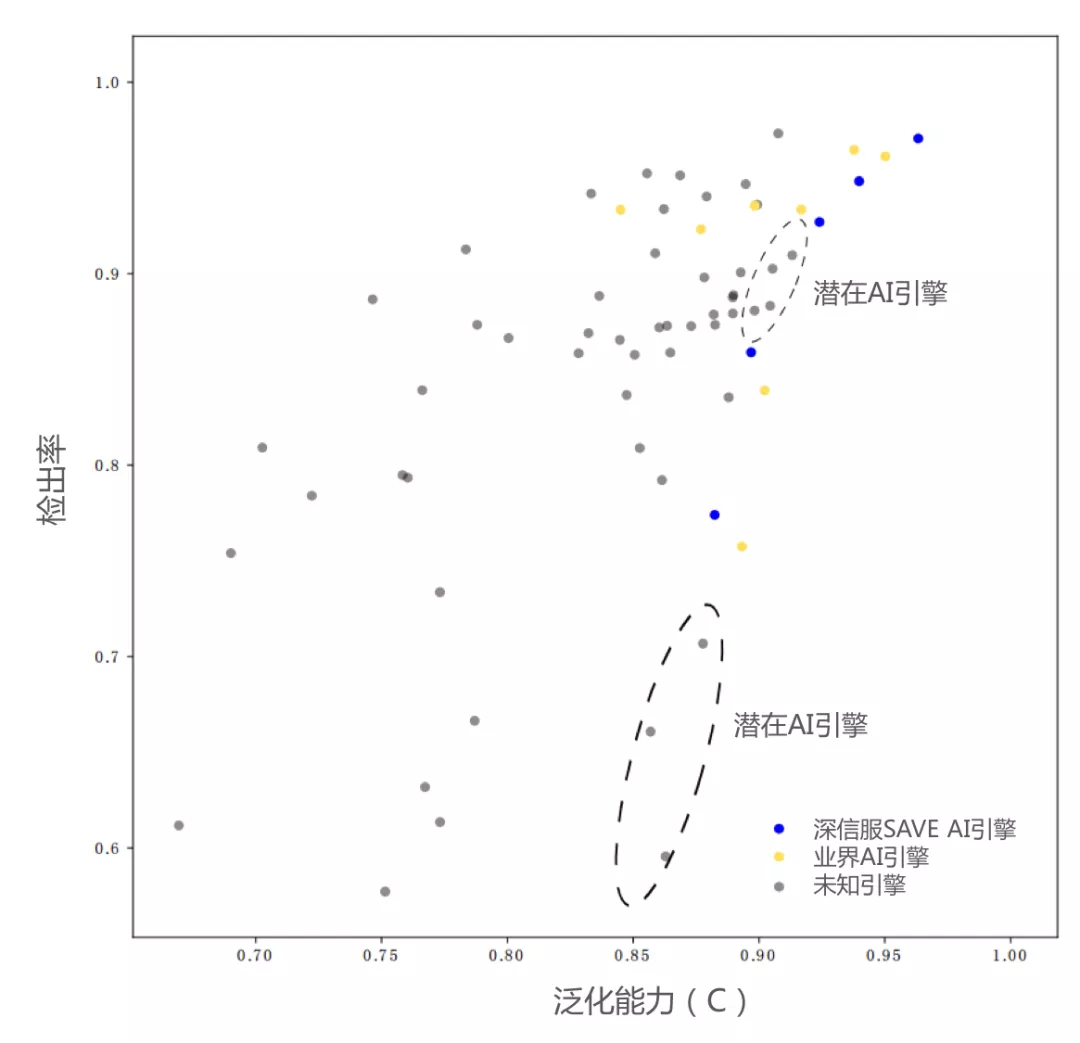
▲业界引擎的泛化能力分布