随着大模型在信创环境中的普及,国产大模型在政务、金融、能源、运营商等行业的规模部署,大模型的安全治理正从“功能性补丁”向“体系化能力建设”演进,安全风险重心也从“模型训练阶段”向“模型使用阶段”转移。
国内外研究表明,大模型安全不仅仅是单点问题,是“输入安全 + 输出安全 + 推理链安全 + 系统安全 + 安全审计”的综合工程。而内容安全风险(Content Safety Risks)成为当前大模型使用过程中最突出的问题。
在信创环境下,由于业务数据高度敏感、监管要求更高、运行环境隔离且强调“可控可管”,单位不能仅依赖大模型自身安全能力。因此,在选型大模型安全防护产品时,应把实时内容安全监测、敏感信息自动过滤、动态风险干预、上下文审计作为核心能力。
一、大模型安全风险分析
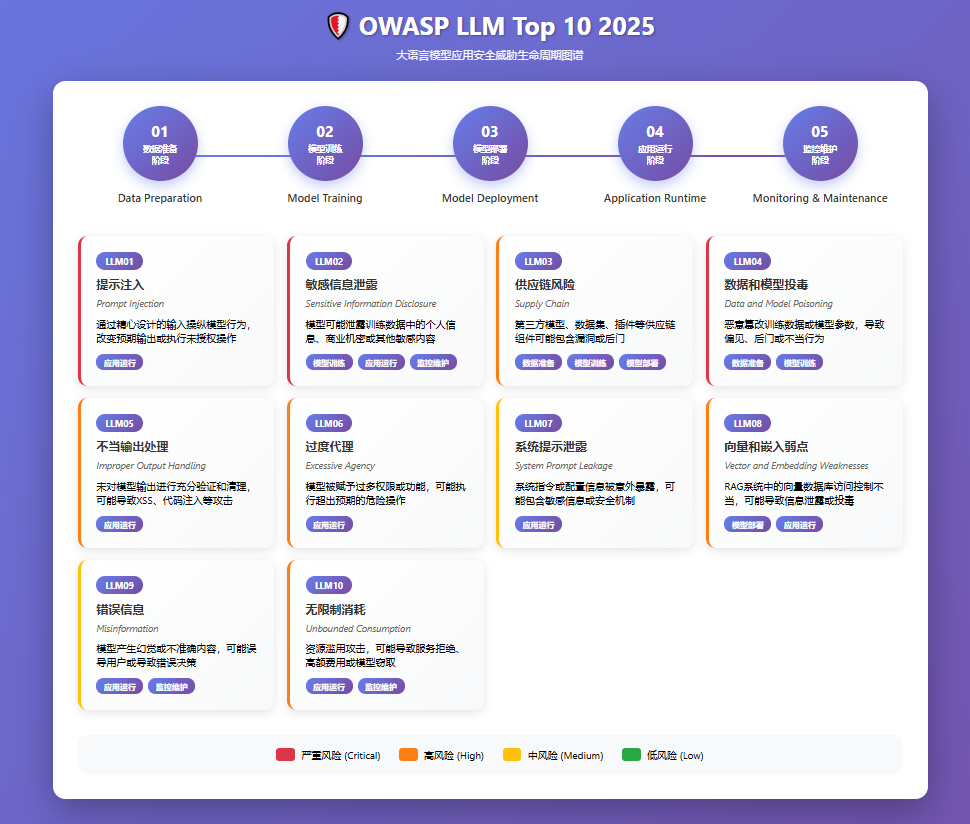
OWASP从大模型生命周期各阶段进行了安全风险分析,包含数据准备、模型训练、模型部署、应用运行和监控维护阶段。
OWASP《大语言模型人工智能应用Top 10安全威胁 2025》
OWASP 发布的《大语言模型人工智能应用Top 10安全威胁 2025》报告表明,应用运行阶段是安全风险最集中的阶段,其中提示注入和敏感信息泄露更是被列入严重风险。这些风险都与内容安全息息相关,极有可能导致敏感信息泄露,而大模型很难靠自身能力解决这些安全风险,外置的大模型内容安全防护能力成为了近期关注和研究的重点。
二、信创环境下大模型安全防护的必要性
在信创场景中大模型的使用有其特殊性要求,与公共云/外部API不同,信创系统更强调对敏感数据的可控性——不仅是网络隔离,更是模型在推理、输入、输出上可能泄露敏感信息的风险管理。主要体现在以下几个方面:
(一)数据敏感度高,泄密产生的代价巨大
信创行业的数据多涉及国家政务数据、涉密或敏感信息,一旦泄露将造成严重政治和安全风险。大模型可能在以下过程中泄露敏感数据:
输入端泄露:内部工作人员将未脱敏的敏感文件、内部代码直接输入模型。
输出端泄露:模型根据已有学习能力推断或“复述”敏感信息,如内部接口、策略、人员信息等
(二)大模型固有安全风险无法完全避免
即使大部分模型具备 RLHF、红队测试等机制,但仍然不可避免地存在过度推理(hallucination)、数据照搬复现(regurgitation)、Prompt 注入攻击(prompt injection)以及规避检测生成敏感内容的能力,这些风险在信创环境中显然是不可接受的。
(三)信创要求“安全可控”,不能仅依赖模型供应商
尽管市面各类主流大模型已具备基础的安全审查能力,但审核机制的侧重点主要集中在通用领域,对于国家秘密、工作秘密和商业秘密等敏感内容的审核能力仍是缺乏。
如果没有强制的内容安全“护栏”,大模型本身并不能保证内容符合安全、合规、风控要求,因此不能仅依赖模型提供方,必须在模型外侧构建安全屏障。
(四)国家政策法规对大模型在政务领域应用提出新要求
中央网信办、国家发展和改革委员会印发的《政务领域人工智能大模型部署应用指引》指出:采取加装保密“护栏”等措施,防止国家秘密、工作秘密和敏感信息等输入非涉密人工智能大模型,防范敏感数据汇聚、关联引发的泄密风险。
因此,在信创环境中,最重要的不是模型本身能力是否足够强大,而是模型在使用过程中是否能保证“输入不违规、输出不越界”。实践证明,传统的安全防护措施无法实时监测单位内部对大模型的使用情况,也无法有效防止重要敏感数据、商业秘密数据的泄露。
三、信创环境下大模型内容安全防护关键要点
针对大模型内容安全风险,在信创环境中,大模型内容安全防护体系应解决以下四类核心问题:
(一)输入敏感信息泄露防护
内部员工可能在对话中无意或有意输入敏感信息,例如:个人隐私(姓名、电话、地址、证件号)、内部系统信息(账号、口令、服务器地址)、内部文件(机密文档、源代码)等,大模型内容安全防护体系必须具备输入侧的敏感数据发现、脱敏、拦截能力。
(二) 输出内容违规与敏感信息二次泄露
大模型在输出内容时可能会对用户输入的敏感信息进行复述造成二次泄露,输出内容有可能包含违规、敏感信息等,大模型内容安全防护体系需通过内容检测模型对输出进行实时审核与阻断,确保没有敏感信息被扩散。
(三)调用行为的审计与溯源
信创场景要求模型使用全程可控,因此需要做到:会话审计、操作溯源、敏感事件记录、操作留痕,这是满足监管与安全合规的关键。
四、信创环境下大模型内容安全防护核心能力
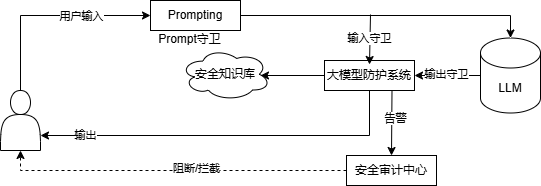
信创环境下大模型内容安全防护核心能力应包含以下几点:
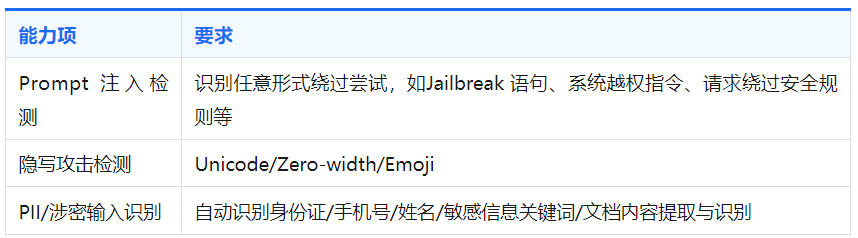
(一)输入安全
输入安全防护的核心能力包括敏感词的识别、个人隐私数据检测(PII)、代码片段识别、国家秘密/工作秘密/商业秘密识别。主要包含以下维度:
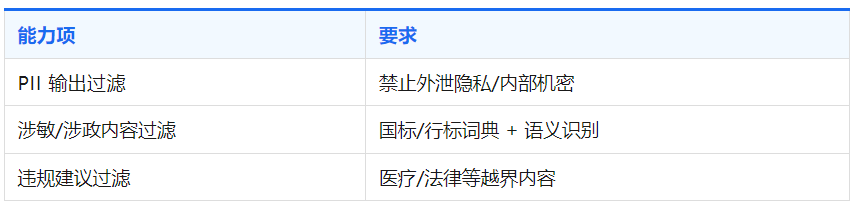
(二)输出安全
输出安全防护的核心能力主要包含以下维度:
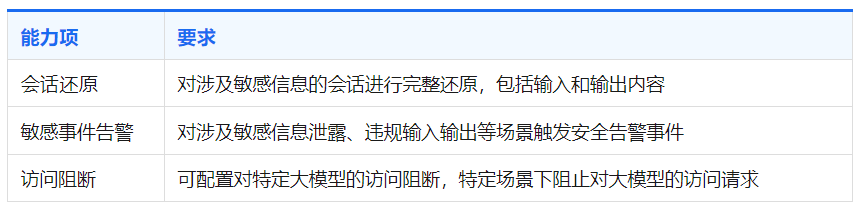
(三)安全审计
安全审计能力是信创场景中必不可少的能力,要求具备会话还原、敏感事件告警、访问行为分析等能力。
(四)信创适配能力
大模型防护产品需满足对主流国产芯片、操作系统和中间件的适配,可在内网隔离环境部署,兼容主流国产大模型。对单位办公网络环境做到“零改造”配置,不影响正常办公终端的使用。
五、中孚数盾 - 终端大模型智栏系统
1、产品概述
为有效应对大模型在应用运行阶段带来的数据泄露风险,中孚推出终端大模型智栏系统,围绕终端应用大模型系统业务场景,依托多项识别检测技术,实时监测用户与大模型交互内容,精准识别涉及国家秘密、工作秘密、商业秘密等敏感信息泄露风险,即时触发告警并支持对违规主机实施访问控制,有效保障单位大模型应用的内容安全。
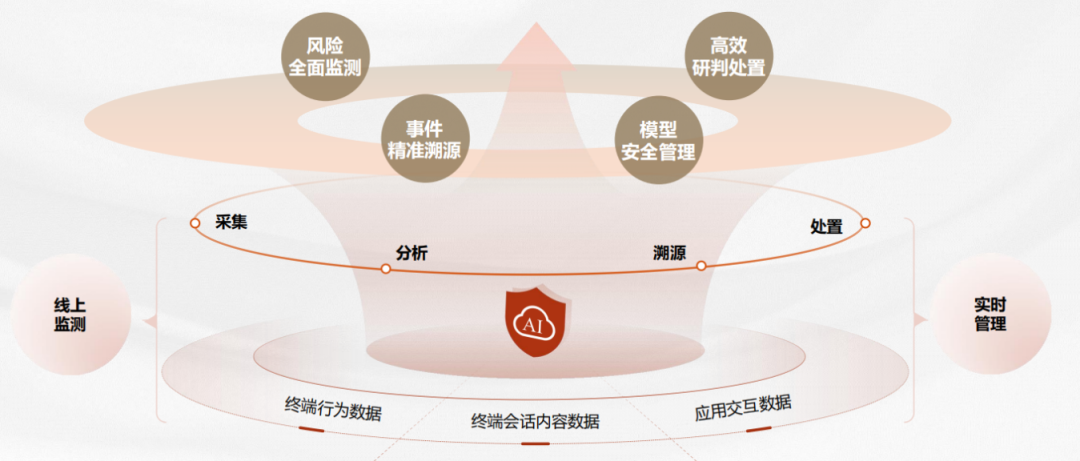
2、功能介绍
中孚大模型智栏系统基于自研的检索、识别、分析等技术引擎的支撑,实现对大模型内容安全的防护和管控,精准还原用户与大模型交互会话上下文,实时监测大模型窃泄密风险,并对单位内的大模型资产进行统一管理。系统总体功能设计如下:
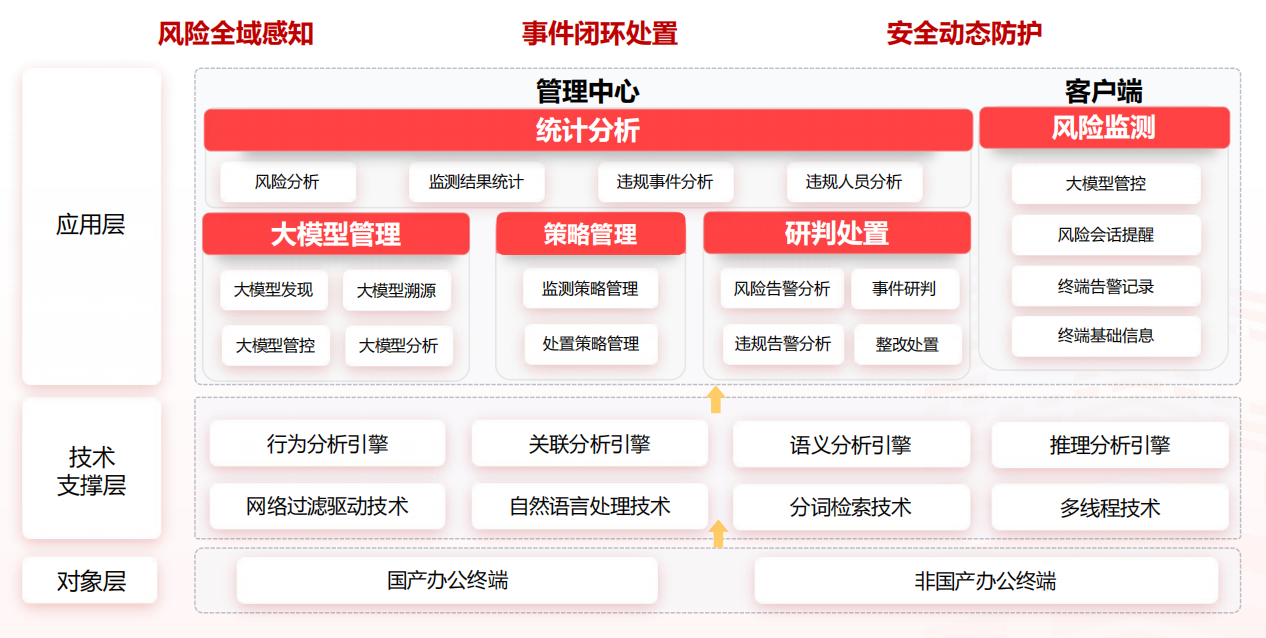
(1)对象层
提供对主流国产化终端及非国产化终端的全面适配,对单位全面终端资产大模型内容安全监测。
(2)技术支撑层
运用多种自研的检测、识别、分析技术对大模型窃泄密风险进行识别发现,基于内置的语义分析、关联分析、行为分析、加密流量分析等引擎,采集终端的行为、网络流量信息,结合标密规则库、研判规则库、大模型规则库等,及时精准发现识别敏感内容和违规行为。
(3)应用层
应用层包含管理中心和客户端,管理中心包含告警事件管理、智能研判推荐、大模型管理等功能。客户端执行管理中心下发的监测策略,并及时向管理中心同步终端的数据安全风险监测结果及终端状态。
3、产品优势
识别快,管控准
基于自研网络协议流量解析引擎,快速精准识别主流大模型网站的对话内容,有效穿透HTTPS加密协议,为大模型访问行为提供实时、精准的管控支撑。
维度多,态势清
依托大模型资产台账,构建多维度可视化视图,结构化整合模型基础信息与访问行为数据,实现模型、单位、人员/用户等多层级风险动态分析,全面清晰呈现安全态势。
策略活,检测准
支持按大模型类型、用户属性、组织结构等多维灵活配置策略。针对不同模型特性(公域/私域)设置差异化的检测内容,实现精准防护,构建具备智能分级能力的多维防护体系。
覆盖全,溯源准
从传统文件监测扩展至HTTPS加密对话内容监测,通过关联分析引擎精准构建对话与文件关系链,依托溯源机制快速定位违规主机及文件位置,全面提升信息安全合规管控能力。
易部署,零感知
系统兼容密保卫士及主流软件分发平台,实现终端无感知部署,无缝对接现有运维体系。告警窗口支持界面样式及响应时长的个性化配置,内置勿扰模式,后台静默审计,用户使用过程无感。
4、技术特点
协议数据无感解析
通过自研网络协议流量解析引擎,实现终端与大模型对话内容的无感解析与内容监测,全程不影响正常业务运行并支持特定网站、论坛、应用的内容监测。
融合行业敏感内容分析技术
依托公司多年行业积累的敏感内容分析技术和知识库,实时监测用户与大模型交互内容,对会话内容、文件附件进行监测,支持国家秘密、工作秘密、敏感词等检测类型,发现违规行为立即提醒。
自研算法精准管控
基于自主研发的大模型检测算法,精准识别并管控终端访问主流大模型行为。
会话完整还原
支持还原原始对话内容,关联对话文件,汇聚输出内容保存至文件全链路,为溯源分析提供数据支撑。
事件精准溯源
敏感内容与本地文档建立关系链,建立对话过程与文件关联关系,基于文件分布与扩散路径生成实时关系图谱。
“以模治模”智能高效研判
基于大模型构建智能研判引擎,实现高风险事件精准识别与处置闭环,提升安全处置效率与准确性。
在信创环境中,大模型已经成为提升业务效率的重要辅助工具,但其带来的失泄密风险同样不可忽视。安全、合规、可控地使用大模型,外置的大模型安全防护产品必不可少。
一个优秀的大模型安全防护产品不仅要能识别和阻断敏感数据泄露,还要具备信创适配、审计溯源等能力,从而真正实现 “安全大模型,可控大模型” 的目标。中孚终端大模型智栏系统依靠其精准识别、灵活管控、全面覆盖、高效便捷的特点,为大模型安全防护提供强力保障。